Pretest | Reliabilität | Validität | Literatur
Ein Pretest ist, wie der Name schon sagt, ein Test, der vor der eigentlichen Datenerhebung durchgeführt wird. Er soll dazu dienen, die Qualität von Erhebungsinstrumenten wie z. B. Fragebögen oder Codebüchern zu verbessern. Dafür wird vor der Haupterhebung ausprobiert, ob das Instrument reliabel funktioniert und man mit der Datenerhebung beginnen kann.
Fragen, die ein Pretest u. a. beantworten soll:
|
Im Rahmen des Pretests soll eingeschätzt werden, ob die gewählten Kategorien dem empirischen Material und der Fragestellung gerecht werden. Zudem ermöglicht er bei Beteiligung mehrerer Personen an der Haupterhebung, die Codierungen aller Codierer zu vergleichen.
Das Ziel eines Pretests ist es also, das Risiko von Misserfolgen zu verringern und das Codebuch immer dann weiter zu verbessern, wenn der Pretest Probleme, Ungenauigkeiten oder Verständnisschwierigkeiten offenbart. Zudem soll der Pretest dazu dienen, die Zuverlässigkeit (Reliabilität) des Instruments zu prüfen. Dabei ist zu beachten, dass der Pretest eine angemessene Anzahl an Untersuchungseinheiten untersucht, um die Bedingungen der eigentlichen Erhebung möglichst realistisch darzustellen.
Darstellung von Vollständigkeit und Trennschärfe und möglichen Problemen bei Kategorienbildung (Rössler 2005: 94):

Die Sicherstellung der Reliabilität ist die zentrale Herausforderung jedes Codebuchs. Sie lässt sich jedoch durch Codiererschulung, Pretest und Reliabilitätstest in den Griff bekommen.
Die Reliabilität eines Messinstruments heißt Zuverlässigkeit der Messung. Bei wiederholter Messung sollte das gleiche Ergebnis erzielt werden. (Rössler 2005: 183)
Wenn bei wiederholter Durchführung der Messung mit demselben Material das gleiche oder zumindest vergleichbare Ergebnisse herauskommen, nennt man die Messung reliabel, sie ist also zuverlässig. Zur Veranschaulichung der Reliabilität eignen sich Beispiele aus dem Alltag: So sollte, wenn man eine Packung Mehl wiegt, nach mehrmaligen Wiegen immer das gleiche Gewicht angezeigt werden. Die Küchenwaage misst in diesem Fall reliabel.
Bei der Inhaltsanalyse wird die Reliabilität unter anderem mit einem Parallel-Test-Verfahren ermittelt: Zwei oder mehr Codierer bearbeiten die gleichen Inhalte und vergleichen anschließend ihre Codierungen miteinander.
Bei einer Inhaltsanalyse spielt die Reliabilitätsmessung eine große Rolle. Der Grund dafür ist, dass die gewonnenen Daten auf einer für alle Beteiligten nachvollziehbaren und einheitlich durchgeführten Messung beruhen sollten, damit die Ergebnisse mit demselben Instrument jederzeit reproduziert werden können. Das ist genau das, was die Reliabilitätsmessung macht: Sie wiederholt Messungen anhand desselben Materials, um sicherzustellen, dass es nicht zu Fehlern während der Datenerhebung kommt.
Es gibt drei verschiedene Arten der Reliabilitätsmessung nach Rössler (2005: 185):
|
1. Intercoder-Reliabilität: Wie gut stimmen die Codierer bei der Verschlüsselung desselben Materials überein? 2. Intracoder-Reliabilität: 3. Forscher-Codierer-Reliabilität: |
Bei der Intercoder-Reliabilität vergleicht man die Codierungen von jeweils zwei Codierern miteinander (siehe Parallel-Test-Verfahren oben). Normalweise kommt im Rahmen des Pretests ein Reliabilitätstest zum Einsatz, der dem Forscher bei der Einschätzung hilft, ob seine Einweisung für die Codierer ausreichend war, um mit der Feldphase beginnen zu können.
Die Intracoder-Reliabilität wird berechnet, indem Codierer zu Beginn und am Ende der Feldphase die gleichen Texte codieren und die Ergebnisse dann verglichen werden. Unter anderem kann so gemessen werden, ob eine Gewöhnung eintritt oder Kategorien im Laufe der Zeit unterschiedlich verstanden werden.
Darstellung der Vergleichsprozesse bei Reliabilitätstest (Rössler 2005: 186):

Bei der Forscher-Codierer-Reliabilität wird überprüft, inwiefern die Codierungen des Forschers mit denen der Codierer übereinstimmen. Damit zeigt sich, inwieweit die Intention des Forschers verstanden wurde in welchen Bereichen des Kategoriensystems noch mehr geschult werden muss.
Nur mit einem Reliabilitätstest kann die Qualität der Codierung mathematisch überprüft werden. Dabei sind nach Rössler (2005: 186) drei Grundfragen zu klären:
1) Was gilt als Übereinstimmung und Abweichung?
Bei den meisten formalen Kategorien (Datum, Zahl der Bilder, Medium) und einfachen Bewertungskategorien (positive oder negative Tendenz im Artikel) ist eine Übereinstimmung oder Abweichung sehr eindeutig zu erkennen und muss auch als solche gewertet werden.
Bei Kategorien mit hierarchischen Inhaltskriterien (Tendenz: stimme voll zu, eher zu, etwas zu, gar nicht zu) ist das schon schwieriger. Ebenfalls zu Abweichungen führen häufig thematische Variablen: Wenn zum Beispiel zwei Codierer entscheiden müssen, um welches Thema es sich in einem Artikel handelt, dann muss festgelegt sein, inwiefern die unterschiedlichen Codierungen als Abweichung oder Übereinstimmung zu bewerten sind. Geht es beispielsweise in einem Artikel um das Image und die gegenseitige Interaktion von Hillary Clinton und Donald Trump, entscheiden Codierer möglicherweise verschieden, ob es sich um einen Wahlkampfartikel zur Präsentation der Kandidaten oder um eine Diskussion über private Skandale handelt. In bestimmten Fällen können so auch zwei verschiedene Unterthemen aus demselben Oberthema als Übereinstimmung gewertet werden.
2) Wie berechnet sich der Grad der Übereinstimmung?
Eine einfache Möglichkeit, den Grad der Übereinstimmung zu messen, ist der Reliabilitätskoeffizienten nach Holsti. Zur ersten Orientierung soll dieser hier genauer betrachtet werden:
Reliabilitätskoeffizient nach Holsti:
R = 2* CÜ / (CA + CB)
R: Reliabilitätskoeffizient der Codierung
Cü: Zahl der übereinstimmenden Codierungen
CA: Zahl der Codierungen von Codierer A
CB: Zahl der Codierungen von Codierer B
Der ermittelte Wert ist eine Zahl zwischen 0 (keine Reliabilität) und 1 (perfekte Reliabilität). Ab einem Reliabilitätswert von mindestens 0,80 gilt die Übereinstimmung als zufriedenstellend und eine hinreichende Qualität als vorhanden.
Ein weiterer Koeffizient ist Krippendorffs α. Es berücksichtigt unter anderem die Anzahl der Ausprägungen einer Kategorie. So wird bei Krippendorff die Wahrscheinlichkeit der Übereinstimmung miteinberechnet. Die Wahrscheinlichkeit, dass zwei Codierer bei einer dichotomen Kategorie eine Übereinstimmung haben ist somit größer als die Wahrscheinlichkeit, dass sie sich beispielsweise bei einer thematischen Kategorie mit mehr als zehn Auswahlmöglichkeiten für die gleiche Ausprägung entscheiden.
3) Wie viel Material muss für den Reliabilitätstest bearbeitet werden?
Als Mindestanforderung gelten 30 bis 50 Codierungen pro Kategorie. Um jedoch eine noch höhere Reliabilität zu garantieren, wären 200 bis 300 Codierungen pro Kategorien besser.
Validität einer Erhebung bedeutet Gültigkeit der Messung; sie gibt an, ob ein Instrument tatsächlich das misst, was es messen soll. (Rössler 2005: 183f.)
Die Validität von Ergebnissen lässt sich deutlich schwieriger beurteilen als ihre Reliabilität, denn hierbei geht es darum, wie angemessen die gewählten Kategorien die Forschungsfrage abbilden und ob die Ergebnisse vor dem gesamten Forschungshintergrund sachlogisch gültig sind. Ob eine Vorgehensweise gültig genannt werden kann, wird anhand von unterschiedlichen Kriterien beurteilt.
Es gibt vier Typen von Validitätsprüfung:
|
1. Analysevalidität
2. Inhaltsvalidität 3. Kriteriumsvalidität 4. Inferenzvalidität |
Analysevalidität ist im Prinzip nichts anderes als die Forscher-Codierer-Reliabilität: Wie gut der Codierer die Zielsetzung, Forschungszweck und -logik verinnerlicht hat, ist eine erste Art von Validitätsmessung, die über die reine Zuverlässigkeit des Instruments hinausgeht.
Die Analysevalidität ergibt sich aus einer Reliabilitätsberechnung zwischen Forschern und Codierern; sie ist damit die einzige Art von Validität, die sich quantifizieren lässt. (Rössler 2005: 194)
Der zweite Validitätstyp ist die Inhaltsvalidität, welche die Gültigkeit der Messung beschreibt. Im Rahmen ihrer Prüfung kann festgestellt werden, inwiefern der Test auch das misst, was er testen soll und ob sich das Messverfahren eignet, um das gewünschte Ziel zu erreichen. Wenn die Werte einer Messung zum Ziel führen, nennt man sie valide.
Beispiel Intelligenztest: Es ist nicht möglich, die Intelligenz von Menschen zu messen, indem man ihnen verschiedene Rechenaufgaben gibt, denn die Rechenfertigkeiten stellen nur einen Aspekt von Intelligenz dar. Daher sollte man bei der Konzeption des Instruments (Operationalisierung) genau definieren, welche Dimensionen Intelligenz umfasst und treffende Kategorien finden, damit die gewählten Kategorien das theoretische Konstrukt möglichst exakt abbilden.
Aussagen über die Inhaltsvalidität betreffen die Vollständigkeit des Instruments und lassen sich zum Teil aus Vorüberlegungen, zum Teil aus Codierungen und Codierverhalten ableiten. (Rössler 2005: 195)
Die Kriteriumsvalidität zieht zur Sicherung der Gültigkeit auch Außenkriterien heran, die sich aus anderen Studien mit ähnlichen Fragestellungen und Vorgehensweisen ergeben. Die Kriteriumsvalidität ist zum Beispiel dann hoch, wenn sich die Ergebnisse einer Studie durch andere Inhaltsanalysen stützen lassen.
Die Kriteriumsvalidität benutzt den Vergleich mit externen Quellen und vergleichbaren Erhebungen, um die Plausibilität der Ergebnisse einer Inhaltsanalyse einzuschätzen. (Rössler 2005: 196)
Die Inferenzvalidität ist mit der Kriteriumsvalidität verwandt. Sie hinterfragt, ob Interpretationen und Rückschlüsse auf Kommunikator und Rezipient, die auf Basis der Inhaltsanalyse getroffen wurden, valide sind. Auch hier werden externe Quellen wie z.B. offizielle Statistiken miteinbezogen.
Zur Beurteilung der Inferenzvalidität sind meist externe Erhebungen mit einem anderen methodischen Zugriff erforderlich, um die Gültigkeit weiter gehender Schlussfolgerungen aufgrund der Inhaltsanalyse zu belegen. (Rössler 2005: 196)
Darstellung der Begriffe Reliabilität und Validität anhand einer Zielscheibe (nach Röhring et al. 2009: 186)
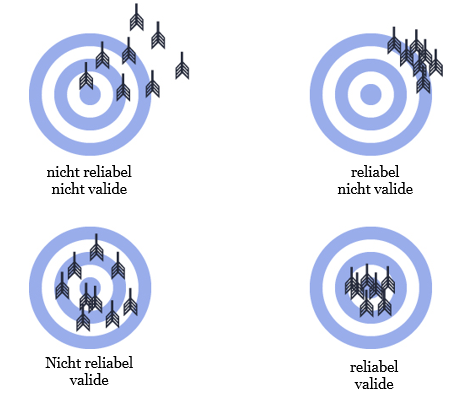
Die Anordnung der Pfeilspitzen auf den Zielscheiben verdeutlicht die Begriffe Reliabilität und Validität:
- Reliabel bedeutet in dem Fall, dass die Pfeile alle in einem sehr engen Feld auftreffen, was im übertragenen Sinn bedeutet, dass mehrere Datenerhebungen zu sehr ähnlichen Ergebnissen kommen.
- Valide bedeutet in dem Fall, dass die Pfeilspitzen möglichst nah um den Mittelpunkt angeordnet sind und somit den Kern der Forschungsfrage möglichst exakt treffen.
Weitere Erklärungen zur Reliabilität und Validität finden sich hier.
Bredner, Barbara (2003-2016). Reliabilität, Validität und Objektivität. Zugriff am 13.12.16.
Brosius, Hans-Bernd/Haas, Alexander/Koschel, Friederike (2015): Methoden der empirischen Kommunikationsforschung: Eine Einführung. Wiesbaden: Springer-Verlag.
Früh, Werner (2007): Inhaltsanalyse. Konstanz: UVK-Verl.-Ges.
Gabler Wirtschaftslexikon: Validität. Zugriff am 13.12.2016.
Röhrig, Bernd/du Prel, Jean Baptist/Blettner, Maria (2009): Studiendesign in der medizinischen Forschung. In: Deutsches Ärzteblatt, Jg. 106(11), S. 184-189. Zugriff am 07.01.17
Rössler, Patrick (2005): Inhaltsanalyse. Konstanz : UVK-Verl.-Ges.
Scheufele, Bertram/Engelmann, Ines (2009): Empirische Kommunikationsforschung. Konstanz: UVK-Verl.-Ges.